上周五同事分享了design patterns in networks,里面很多patterns都是做路由器防火墙这样的转发设备之所以高效的精髓所在。「程序人生」的读者多为互联网应用(系统)开发者,对这些design patterns未必了解,所以这篇文章我干脆抽取同事分享内容和互联网系统开发关联较大的patterns,讲讲在互联网项目上的应用场景,借花献佛。
这两个概念几乎是networks 101的入门概念。Juniper上世纪末兴起的重要原因之一就是严格区分界定control plane和data plane,然后用ASIC实现data plane。Data plane是指一个网络设备用于报文转发的component,它的效率决定整个设备的效率,一般会由硬件完成。Control plane是指一个设备协议相关的部分,可以没有数据转发那么高效。
当你打开浏览器访问google时,internet上面的网络设备就开始紧锣密鼓地工作,目的只有一个,把你的请求转发到google的服务器。学过网络课程的人都知道,这其中运行的网络设备就是路由器。路由器需要有足够快的转发速度,延时越小越好 —— 这考量的是data plane的效率;而data plane转发决策的依据 —— 路由,则由control plane的协议处理来完成。
在一个互联网系统上,似乎没有control plane和data plane较为清晰的界定。我们不妨粗暴地认为用户访问的路径为data plane,而admin相关的路径为control plane。对于data plane上的工作,我们可以单独划分一个集群来处理,力求每个request都得到最高效地处理,而control plane上的工作,则可以尽可能用比较小的资源完成。这里最重要的原则是:data plane和control plane做到路径分离,让data plane上的大量requests不致于影响control plane的正常工作;同时control plane上的慢速任务不致于拖累data plane的访问速度。
做防火墙,少不了会遇到first path和fast path的概念。防火墙处理的是双向的数据流,需要记录状态,所以有session的概念。在first path里面,走一个慢速的全路径,创建session,在fast path里面,则可以利用session里面的各种信息快速处理数据报文。
在互联网系统上,类似的mapping很好建立。在一个需要用户登录的系统里,用户登录的整个过程可以被视作first path,随后的访问可以被视作fast path。
用户登录是一个复杂的过程,不仅仅是验证用户合法性这么简单。在前台尽快给出用户登录后页面的同时(responsiveness很重要),后台需要加载一系列用户相关的数据到缓存(比如redis)中,以便用户在随后的访问中能够快速获取。加载的数据可以是用户的朋友信息,用户可能会访问的热点数据,各种各样的counters等等。
当然,first path/fast path的概念不仅仅适用于登录和登录后的访问,还有很多其它的应用场景。比如说一个规则系统,首次访问时从规则引擎中抽取用户相关的规则进行编译和缓存,之后的访问则直接从编译好的规则缓存中高效读取。
注意first path/fast path的概念是相对的,就像分形几何一样,first path里面可以再区分中first path/fast path,fast path里也可以再区分出first path/fast path,不断迭代下去。这样做的目的是,不断地优化系统中最常用的80%的路径,让它们的效率最大化。
Slow path/fast path和first path/fast path很类似,但又不尽相同。就用户登录而言,我们假定(或者有实际数据)80%的用户通过用户名/密码登录,那么用户名/密码登录就要置于fast path下,而其它的诸如LDAP,OpenID,XAuth登录方式置于slow path下。
这样区分fast path/slow path的好处是,一旦有需要,我们可以把对应的代码用更高效的方式实现,比如说整个系统是python实现的,系统中的一些fast path处在用户访问的热点区域,那么可以考虑用go来实现。
在网络设备中,queue无处不在,几乎成了最基本的操作。一个数据报文从硬件上来之后被放到了driver的queue上,然后在系统处理的各个层级,不断地被enqueue/dequeue。Queue有很多好处,比如说延迟处理,优先级,流量整形(traffic shaping)。
一个复杂的互联网系统很多时候也需要queue来控制任务处理的节奏。比如说email验证这样的事情,可以不必在当前的request里完成,而放到message queue中,由后台的worker来处理。另外,queue可以有不同的优先级,发送email和将图片转换成不同的size显然可以放入不同的优先级队列中调度。
对于互联网项目而言,有很多成熟的message queue system,比如RabbitMQ,ZeroMQ。
在网络系统里面,如果一个任务很复杂,需要很多CPU时间,那么该任务可以分解成多个小任务来执行,否则的话,这个任务占用CPU时间过长,导致其他任务无法执行。当一个任务分解成多个小任务后,每个小任务之间由queue连接,上一次处理完成之后,放入下一个queue。这样可以任务调度更均衡。
在互联网项目中,pipeline有很多应用场合。比如说一个workflow里面状态机的改变,可能会执行一系列的操作,然后最终迁移到新的状态。如果这一系列的操作在一个大的function里执行,而非分解成若干个通过queue相连的小操作,那么整个处理过程中的慢速操作会影响整个系统的吞吐量。而且,这样做非常不利于concurrency。
在一个大型系统中,pipeline的程度决定了concurrency的程度。而pipeline的应用程度会影响整个系统架构的吞吐量。有些编程语言,如golang,天然就让你的思维模式往pipeline的方式去转(通过go/chan)。
既然提到了状态机,就讲讲状态机。状态机由两个元素组成:状态;以及状态迁移。状态迁移是由动作引起的,因此一个状态机可以表示为 state machine = {state, event} -> (action, new state)。只要画出一个二维表,就能分析系统所有可能的路径,而且很难有遗漏。在网络设备中,大部分协议都由状态机来表述,比如说ospf,igmp,tcp等等。
在互联网项目中,状态机无处不在。比如说订单处理。一个订单的处理流程用状态机表述再完美不过。下面是我曾经写过的一段示例代码(python):
ORDER_EVENTS = {
(const.ORDER_EVENT_PAYED, const.ORDER_STATE_CREATED): {
'new_state': const.ORDER_STATE_PAYED,
'callback': on_order_event_payed,
},
(const.ORDER_EVENT_PAY_EXPIRED, const.ORDER_STATE_CREATED): {
'new_state': const.ORDER_STATE_CANCELLED,
'callback': on_order_event_cancelled,
},
(const.ORDER_EVENT_CONFIRMED, const.ORDER_STATE_PAYED): {
'new_state': const.ORDER_STATE_CLOSED,
'callback': on_order_event_confirmed,
},
(const.ORDER_EVENT_CONFIRM_EXPIRED, const.ORDER_STATE_PAYED): {
'new_state': const.ORDER_STATE_CLOSED,
'callback': on_order_event_confirm_expired,
},
...
}
最后稍提一下watchdog。一般来说,路由器防火墙这样的网路系统是实时系统,任何一个任务,都应在规定的时间内结束,否则就是系统错误。所以我们需要watchdog来监控任务(有硬件watchdog,也有软件的)。watchdog还可以帮助开发者发现系统中的死锁,过长的循环,任务分配不合理等问题。如果某一任务执行时间过长,它就会阻塞其他任务,如果所有的CPU都被这类任务占用了,系统就无法响应事件,也有可能无法将这些任务调度出去。
在互联网项目中,处理request,处理async task等等都有一系列数量有限的worker。如果某个worker死锁,或者执行时间过长(可能是异常情况)导致「假死」,我们可以用watchdog进程来杀掉这些已经「假死」的worker,让系统的吞吐量恢复到正常水平。如果不这样做,「假死」的worker越积越多,可能会最终导致整个系统 out of service。

【TechWeb】12月2日消息,金山软件发布公告称,于2019年12月2日,金山云集团与某个金山云股东、高级管理人员及中国互联网投资基金(有限合伙)订立购股协议,金山云(作为发行人)同意向中国互联网投资基金投资者发行约5509万股每股票面价值 0.001美元的D+系列优先可转换股份,代价为5000万美元。假设(i)金山云的所有优先股按1:1之转换比例悉数转换为金山云普通股;及(ii)购股权计划项下的所有股份及僱员持股计划(包括信託契据)项下保留以供发行的所有股份获发行,于完成购股协议项下拟进行交易后,金山云将由中国互联网投资基金投资者拥有约1.8868%,而本公司于金山云的股权将由49.1251%减少至48.1982%。金山云将仍为本公司附属公司。董事会进一步宣佈,于购股协议完成时或之前,金山云当时的所有股东将订立经重列股东协议,据此,D+系列优先股持有人有权于以下情况下要求金山云购买彼等持有的D+系列优先股:(i)D系列合资格公开发售未于特定期限内完成;(ii)金山云的任何B系列优先股持有人已根据经重列股东协议要求金山云购买其持有的B系列优先股;(iii)金山云的任何C系列优先股持有人已根据经重列股东协议要求金山云购买其持有的C系列优先股;或(iv)金山云的任何D系列优先股持有人已根据经重列股东协议要求金山云购买其持有的D系列优先股。金山云集团主要从事云技术的研发并提供相关服务。中国互联网投资基金投资者为于中国注册成立的有限合伙,主要从事互联网领域的股权投资。就董事作出一切合理查询后所深知、尽悉及确信,中国互联网投资基金投资者及其最终实益拥有人均为独立于本公司及其关连人士的第三方。
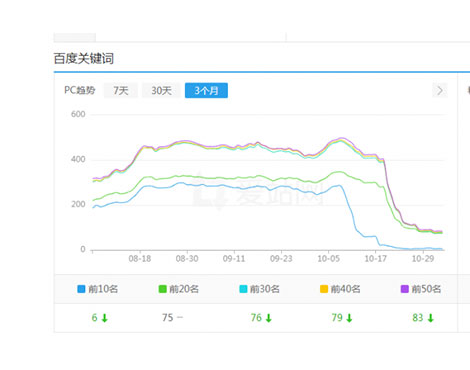
最近一段时间,大家发现很多网站关键词库和流量都在直线下滑,站长圈可以说是哀嚎遍野。即便是一些大站权重站,有些也难逃厄运。如上图所示,图中案例就是一个之前操作过快排而被惩罚的站点。其下场不可谓不悲壮。在这里我们先了解一下快排。现在的快排,主要分为两类:模拟点击;发包技术。其中模拟点击是租用大量的服务器和ip,在服务器上搭建一个模拟浏览器并使用脚本在浏览器上模拟用户的搜索行为,来提高页面在百度的评分。发包技术是直接伪造用户搜索浏览行为参数,直接将数据包post给百度,可以快速的将页面在百度的评分提高。发包技术中不乏上千指数大词3天上首页的案例。这种快排方式严重干扰了百度搜索的市场环境,因此百度在进行了打击快排灰度测试后,开始扩大算法应用范围,其结果就是如今的大量网站的关键词库像瀑布一样直线下降。既然算法已经来了,我们也只有选择原谅,哦不,是选择面对。百度打击快排,最主要的首段就是靠抓取快排的特征。其中发包快排的特征比模拟点击特征明显很多,因此如果您还要继续做快排,对于发包快排的供应商一定要慎重又慎重的选择。那么模拟点击就不会被打击吗?也一样会被打击。做模拟点击的作弊网站,有个很大的特征就是:有大量的词的点击率超过了50%甚至接近100%。这种极其不正常的现象,让百度也有了反击的方向。因此如果还要做模拟点击,就必须降低点击率。否则依然一抓一个死。当然,我在这里并不是提倡大家做快排,既然是快排,就有被惩罚的风险,靠白帽技术安心优化,为更多的用户提供搜索价值,百度自然会将您的网站排名提升上去,自然会将搜索流量像你倾斜。快排就像一杯毒药,你喝或者不喝,都是你的选择。既然百度开始打击了,我们就必须沉着的去面对。如果可以的话,现阶段不要去碰快排这个雷区,安心做优化,做内容,做外链,为真正的搜索用户做好服务,才是最好的选择。上图那样稳定的幸福,又有谁不想要呢?


TOP
 沪公网安备 31010602003962号
沪公网安备 31010602003962号





